Lookign-for-the-Devil-in-the-Details-Learning-Trilinear-Attention-Sampling-Network-for-Fine-grained-Image-Recongnition 是2019年CVPR一篇关于细粒度的文章
文章传送门
一 文章简介
文章提出了一种TASN卷积神经网络,主要要解决现有的注意力机制网络,受注意力区域数目,以及计算量限制的问题
设计思路如图所示

即通过TASN网络,对图像局部区域的特征进行“专注”的学习
二 模型
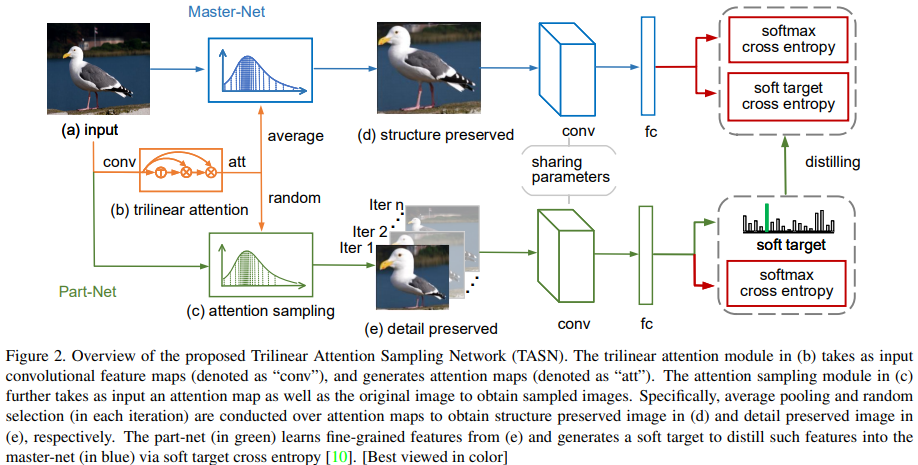 )
)
模型的主体结构主要由三部分构成:
1.trilinear attention:通过通道间的联系,构建通道级别的attention图
2.channel level sampling:对不同的通道区域进行采样
3.feature distiller:通过知识蒸馏以及参数共享,实现对局部特征的融合
将图片输入卷积网络得到卷积特征输入TASN得到通道的注意图,上部分对整个注意力图做average pooling后与原图像经采样后共同输入待训练的卷积神经网络,下部分按照文中的channel level sampling对单个通道注意力图进行采样,采样出单张后与原图像经过采样后输入待训练的卷积神经网络,上下两部分的卷积网络参数共享,上半部分作为训练的结构框架,下半部分通过featuredistiller的方式对卷积神经网络的局部细节进行补充。
三 方法流程
3.1 trilinear attention
trilinear attention的主要结构如图所示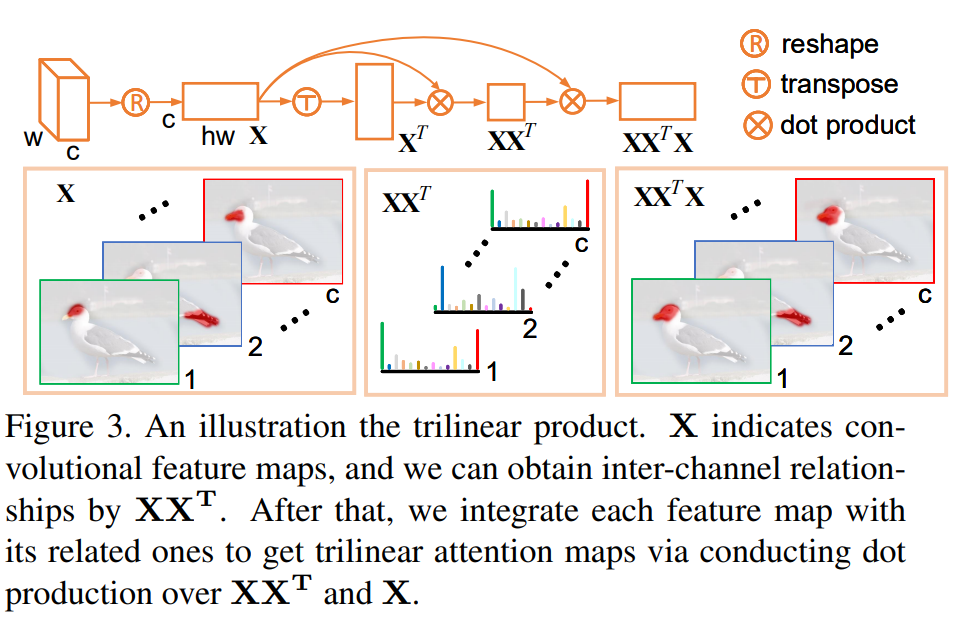 )
)
之前提到过,不同卷积层对特征的不同区域的敏感性是不同的,也就是说,不同卷积层我们可以认为是可以生成不同感知区域的attention 文章根据feature channel的空间关系对通道特征进行整合,将特征图转化为前向传播的注意力图,这种注意力图的生成方式与平常接触的CAM图还是有差别的,
CAM是根据分类loss反向传播得到的特征图,trilinear attention这种特征图生成方式更类似与前向生成的特征图。
文章提出的三线性特征为: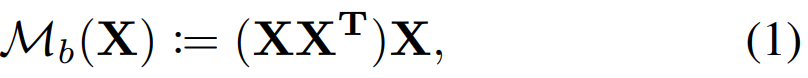
为了提高三线性注意力的有效性,文章提出了一种非线性形式的三线性注意力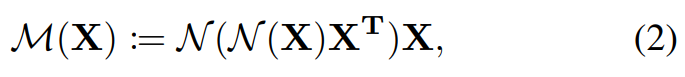
其中N为softmax函数,第一个softmax目的是保持通道级信息在同一尺度上(0-1),第二个softmax在每个通道级特征上进行非线性,目的是更好的突出attention区域。
文章还提到,为了获取位置更加准确的feature map,文章通过改变卷积核移除了resnet网络的两个下采样图,以及增加扩张卷积从而增加卷积网路网络的感受野。
3.2 channel level sampling
文章将原图像与三线注意力图作为输入,分别生成保留结构信息以及局部细节信息的feature,与直接输入原始图像相比,保留的结构去除了没有细粒度细节的区域,因此能够更好的表示辨识部分,细节信息的图像更着重与单个部分,可以保留更具有细粒度细节信息。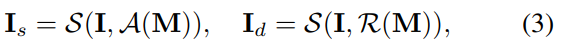
其中,I是输入原图像,M是3.1中生成的attention map,S表示非线性采样,A代表在通道尺度上的average pooling(代表结构信息),R表示从输入attention map随机选取通道的单个feature(局部细节信息)通过不断的训练,每一个channel 都有可能被选到。
这部分比较重要的部分是采样函数S的定义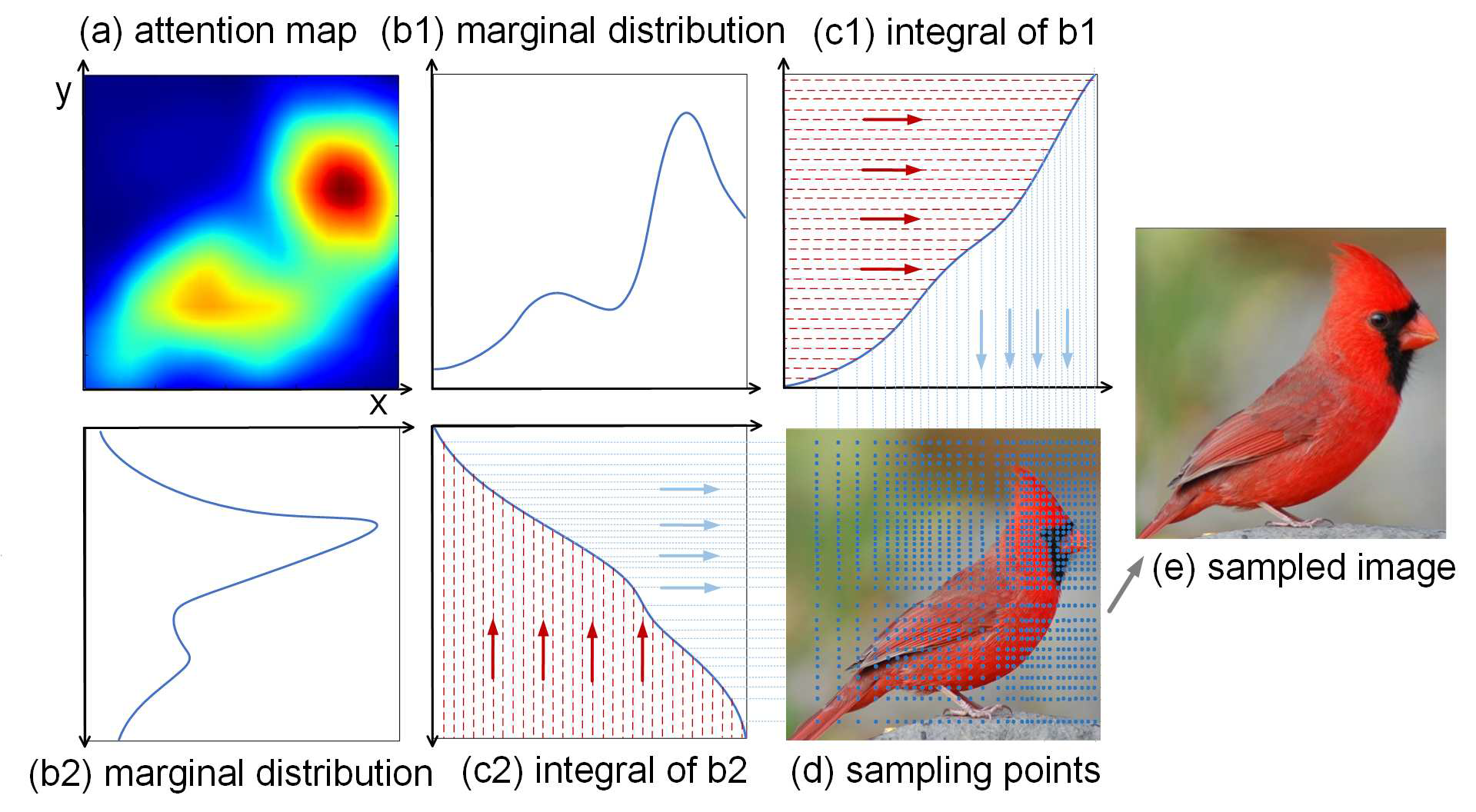
文章将注意力图是做概率权重函数,也就是说具有较大注意力值得区域,有更大的概率被采样到。具体过程为:分别对attention图进行x轴和y轴的最大特征值得映射,生成(b1)和(b2),文章说采用最大值有比较强的代表性以及鲁棒性,对其在x和y轴进行积分,生成(c1)和(c2)曲线,曲线的斜率也就代表着这点特征值得大小,然后对其进行一个反函数的操作
经过反函数后,可以看到图中x,y轴表示图像,关于y=x轴对称了,这样的话,如果对x轴进行均匀采样的话,在原图像,就能采样到更为密集的点,原因就在于,原本那一点的斜率比较大,经过反函数后斜率就变小了,也就是说,均匀采样的话可以在原本密集的区域获取更多的采样点。这也就是为什么(c1)(c2)会一那样的图形进行表示。采样过后生成图e 可以知道,采样出的图像在特征密集点区域更加突出。
3.3 feature distiller
通过知识蒸馏的方式,将网络提取的细节信息,以及结构信息作为Part-Net以及Master-Net网络的输入,如模型图所示,将从Part-Net学到的图像语义细节信息,传输给Master-Net。将获取的结构信息Is 与 Id分别输入参数共享的卷积神经网络中,经过不同的全连接层+softmax获得分别的分类结果Zs和Zd,如下图所示: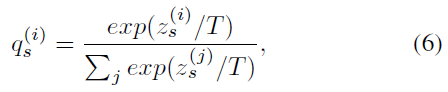
其中T为温度系数,是一个超参数,在分类任务中,绝大多数情况值为1,也就是我们最常见的softmax形式,但是在feature distiller中,T的值不是1 目的是为了让分类结果产生软概率分布。
这样就可以得到Master-Net中的软目标交叉熵。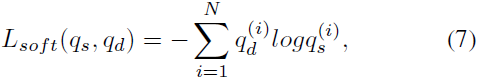
其中qs和qd分别代表经过Zs和Zd经过softmax后的预测概率值
最后,Master-Net的目标函数为: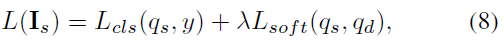
软目标交叉熵的目的在于将网络获取的细节特征传送给Master-Net,在训练过程中,每次从训练的样本中随机选择一个通道信息作为输入,产生不同的细节信息,经过大量训练后,每一个细节都会被补充到结构信息当中,完成了文章最初的设计想法。




