Learning Multi-Attention Convolutional Neural Network for Fine-Grained Image Recognition 是2017年CVPR一篇关于细粒度的文章
文章传送门
一 文章简介
文章提出了一种采用弱监督学习的多注意力的卷积神经网络,主要要解决以下两个问题:
1.当前的细粒度分类方法主要依赖于具有区分度的局部信息或者基于局部的精准信息,少有将二者联系起来的模型。
2.基于局部信息的模型,通常需要手工标注注意力区域,这需要耗费大量人力。
二 文章的亮点
1.由于卷积层不同通道对图像的感知敏感性是不同的,文章利用这一点,在通道特征的利用上下了一定功夫,得到不同通道级别的注意力区域
2.文章针对生成的注意力区域设置了channel group loss,目的是为了让生成的不同通道级别注意力区域更加有信息性以及代表性
三 模型
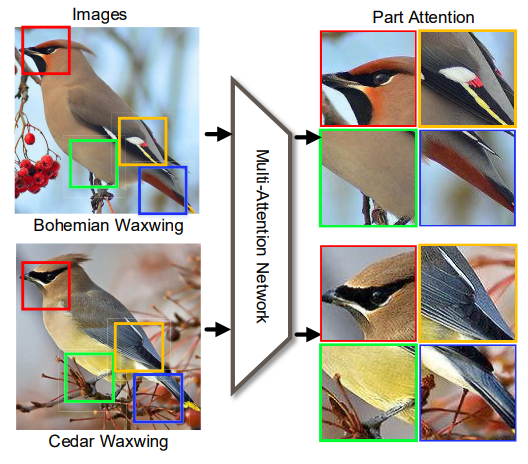
如图3.1所示,文章认为不同的鸟类,在相同部分,如翅膀,嘴尖,爪子上有的微妙的视觉差异,文章主要利用这一点,分别选取鸟类中具有判别性的区域,输入其设计的多注意力网络,实现对鸟类的判别
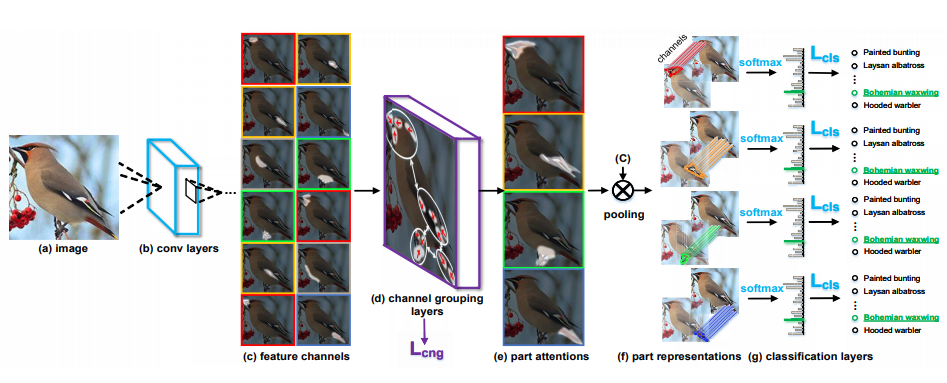
网络的整体结构如图3.2所示,输入一张图片到卷积神经网络,由于卷积层的不同通道对事物的感知能力是不同的,有的卷积层对翅膀可能更敏感,有的可能对嘴尖更敏感(以鸟为例),所以有图3.2(c)中对同一卷积层的通道展开,有不同灰色感知区域的差别,文章通过聚类算法对相同感知区域的卷积通道进行聚类,假设聚类中心为4(图3.2e中的四幅图),对处于同一聚类结果的不同通道卷积层进行通道级求和,就得到了图3.2e的部分,再对其进行归一化处理,sigmoid函数,产生四个不同区域的空间注意力mask,mask主要是用于定位局部特征区域,mask与卷积层的特征进行点乘,便得到了不同区域细化的卷积特征,分别进行softmax分类。
四 方法流程
4.1 通道级特征选取
个人认为是文章最具有创新性的部分
channel grouping 预训练
直接用初始化参数训练,容易造成这部分陷入局部最优解,这就需要对其进行提前的预训练处理
预训练过程中,feature map 每一个channel都会产生信息突出点,也就是被激活的区域,我们可以将激活值最高的区域的()坐标作为这个channel代表特征,用于参与聚类。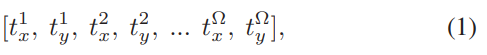
将图4.1的channel 代表特征进行聚类,聚成N簇,在分别对其每一簇进行编码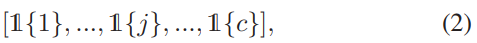
若向量的channel 属于当前簇,则将其设为1,否者设为0,也就是说,假设只有A,B两簇,A簇为【1,0,0,0,1】,那么B簇的编码必为【0,1,1,1,0],即编码后的N簇是互斥的。但是这样的处理方式存在一个问题,那就是无法在同一网络进行端对端的训练。
所以文章采用了用全连接层替代强行0.1编码的方式,改用N组全连接层,每个全连接层收网络的特征,生成一个权重向量di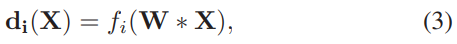
为了让获得的di更加准确,文章需要对全连接层的参数进行预训练,即图4.3的值尽可能的趋近于图4.2的值。经过这样的处理后,我们得到了N个部分的卷积特征掩码,通过图4.4,即feature map 与mask点乘后,通道求和。在经过sigmoid进行归一化处理得到 probabilities map。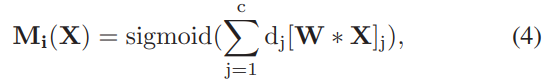
综合起来得到图4.5,channe group 特征的获取方式
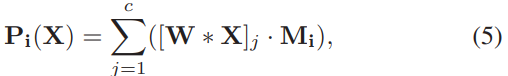
其中,W为全脸层参数,X为输入卷积特征,M为得到的channel attention mask
4.2 损失函数
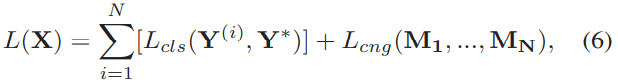
整体损失函数如图4.6所示共有以下两部分构成
分类损失
常见的交叉熵分类损失,N个part损失共同求和优化
channel group part 损失
为了使 channel group part 同一part 距离更近,不同part距离更远,文章提出了DIS 和 DIV 两种损失函数如图4.8,4.9所示
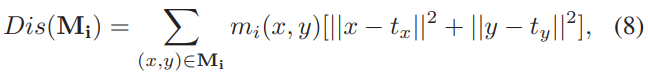
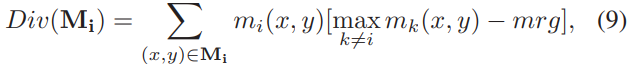
这部分整体损失函数为图4.10
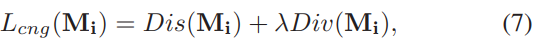
训练方式
文章采用了交替训练的方式,即分类部分与channel group 部分相互强化训练的方式,固定一部分,训练另一部分,直到二者损失均平稳,认为训练完成
五 总结
文章在channel group 那部分设置十分巧妙,通过N组全连接层去替代1.0编码 以及在文章区域信息的把握上值得学习与借鉴。




